
 Внимание!
Внимание!
1. Пользуйтесь тегами кода. - [code] ... [/code]
2. Точно указывайте язык, название и версию компилятора (интерпретатора).
3. Название темы должно быть информативным.
В описании темы указываем язык!!!
  |

| Andrewshkovskii |
 24.11.2009 17:59 24.11.2009 17:59
Сообщение
#1
|
|
Бывалый  Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация:  0 0  |
Вершины – объекты
минимального остовного дерева группируются в кластеры. Выбираются два объекта, которым соответствует минимальное ребро minjdj, где j=1, n-1. Далее эти объекты стягиваются в один кластер (класс, таксон, страту) и процедура шага 2 повторяется до тех пор, пока на n-1 этапе группирования не будет сформирован один кластер, объединяющий все объекты. STOP. 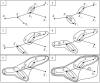 На рис. представлена последовательность группировки объектов в кластеры для заданного на рис.1 примера минимального остовного дерева. Порядок объединения объектов в кластеры отображён на рёбрах, которые связывают объединяемые объекты .Таким образом, первыми объединяются объекты X4 и Х5,которые в МОД связывает минимальное ребро d4 с весом 2. Вторыми объединяются объекты X2и X3, связанные ребром d2 с весом 3 , и так далее, пока на шестом этапе группирования ранее связанные объекты (X1,X2,X3,X4,X5,X6) не будут объединены с объектом X7 ребром с весом 7. И так , перейдем к описанию алгоритма кластеризации на примере : Ребра МОД : Цитата (ИЗ--ВЕС-->В); 1. Е--2328-->Ом 2. В--2732-->И 3. Е--4667-->П 4. Л--5161-->Ом 5. О--6588-->И 7. П--14946-->В И образуемые кластера : (Шаг. №кластера) 1. 1.Е + ОМ значение кластера 2328 2. 1. 2. В + И 2732 3. 1. кластер поглощает вершину П, новый кластер Е+Ом+П 4667 2. 4. 1. поглощает вершину Л, новый кластер Е+Ом+П+Л 5161 2. 5. 1. 2. поглощает вершину О, новый кластер В + И + О 6588 6. 1 поглошает 2 и получается Л+Е+О+П+В+И+Ом 14946 Надеюсь понятно..вот как я понял этот алгоритм вербально : Цикл от i=0 до n-1 Цикл от j=0 до n-1 Если множество вершин ребра/кластераi при пересечении с множеством вершин ребра/кластераj образует не пустое множество если значение ребра/кластераj >=значению ребра/кластераi ТОГДА образуется кластер соединением множества вершин ребра/кластераj и множества вершин ребра/кластераi ИНАЧЕ наше ребро и есть кластер. Правильно ли я понял алгоритм? Вот так его можно описать в коде.. //ribs это объект класса реализующего : |
   |

 
|
| volvo |
24.11.2009 18:15
Сообщение
#2
|
|
Гость |
Можно уточнить, в результате ты что хочешь получить? Так или иначе по окончании работы алгоритма ВСЕ вершины будут принадлежать к одному кластеру. В чем смысл этого всего? Тебе нужно хранить список кластеров с вершинами, входящими в них что-ли?
|
|
|
|
| Andrewshkovskii |
24.11.2009 18:34
Сообщение
#3
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
http://el-niko.ru/lab/1/
Вот тут пример , это программа моего согруппника,только у него алгоритм не основан на ребрах. В результате для каждого среза (срез в данном случае - уникальное значение в МОД) на сайте он изображен снизу слева и справа, слева ввиде дендрограммы, справа в виде спика кластеров..Надо получить правильную дендрограмму, т.е все возможные кластера. Вообще хотелось бы это дело опитимизировать так, что бы проходил наименьшее кол-во шагов. На каждом шаге формируется кластер, его необходимо отправлять во в такой вектор vector < map < int, vector < cluster * > > ; Т.е вектор срезов дендрограммы, где int - значение среза, vector <cluster *> вектор кластеров сформированных на данном срезе. Сообщение отредактировано: Andrewshkovskii - 24.11.2009 18:38 |
|
|
|
| volvo |
24.11.2009 20:46
Сообщение
#4
|
|
Гость |
Шо-то мне не очень понятно, что там твой согруппник сделал... Нет, ну сначала все идет как надо, а потом начинается нечто, не поддающееся объяснению. Смотри, чего я тут наваял (за основу взята твоя же программа для нахождения МОД):
#include <iostream>  (С++ так С++, по-полной) (С++ так С++, по-полной)Данные - оттуда же, из таблицы по ссылке, при "Количество записей = 8". Вот вывод программы (исключая МОД, оно строится правильно): Lantasovo : 0 Чувствуешь? А у него каким-то необъяснимым образом сначала группируются Войновка с Екатеринбургом, и только потом этот кластер объединяется с остальными. Это откуда такое взялось? |
|
|
|
| Andrewshkovskii |
24.11.2009 23:48
Сообщение
#5
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Что-то ты нагромоздил кода, хотя просто я использую QtStl в своем проекте, там попроще с векторами и множествами, да и для представления ребер/кластеров я реализовал отдельный класс( просто выкладывать его сюда мало смысла - всеравно без Qt не получиться скомпилировать)
А твой ответ не совсем ясен( честно скажу, в код не вникал). У него на Срезе 15 обременяются вершины Инская и лянгасово, т.к между ними мин. ребро на срезе 156 к этому ребру/кластеру добовляется вершина Орехово, т.к она связана с одной из вершин в предыдущем кластере(а именно - Инская) следующим мин. ребром с весом в 156..По тому же принципу и Егоршино на срезе 176 добавляется в тот же кластер, далее Омск на срезе 226, Пермь на срезе 239 (т.к все они имею связи через ребра МОД). На 334 срезе связывается Войновка и Екатеринбург, т.к они имею следующее мин. ребро из не использованных, и ни одна из этим вершин не имеется в предыдущих кластерах, поэтому они стают особняком на этом срезе, а после чего у них соединение на Перьми появляется и они объединяются в кластер.. А твои результаты я не понял. Может я плохо объясняю? Пожалуйста, спроси, что именно не понятно - я постараюсь объяснить более человеческим языком. Если надо, скину свои исходники. Приведу всетаки полный код, может что яснее странет.. Сначала класс кластер/ребро : интерфейс : #ifndef CLUSTER_H Реализация ... : #include "cluster.h" А вот алгоритм кластеризации : void Model::calculateNewClustersModel(QStandardItemModel * spanningMatrixModel) И вот вывод моего кода для "Вагонооборот" при 19 строках : Цитата "|Курган Инская |" 152 SIZE 2 "|Войновка Бердяуш |" 416 SIZE 2 "|Алтайская Орехово |" 428 SIZE 2 "|Пермь Нижний Новгород |" 461 SIZE 2 "|Екатеринбург Челябинск |" 576 SIZE 2 "|Войновка Бердяуш Богданович |" 593 SIZE 3 "|Смычка Агрыз |" 799 SIZE 2 "|Алтайская Орехово Каменск-Уральский |" 1264 SIZE 3 "|Пермь Екатеринбург Нижний Новгород Челябинск |" 1305 SIZE 4 "|Алтайская Орехово Смычка Агрыз Каменск-Уральский |" 1453 SIZE 5 "|Курган Инская Юдино |" 2296 SIZE 3 "|Егоршино Пермь Екатеринбург Нижний Новгород Челябинск |" 2325 SIZE 5 "|Егоршино Пермь Омск Екатеринбург Нижний Новгород Челябинск |" 2328 SIZE 6 "|Курган Войновка Инская Бердяуш Юдино Богданович |" 2732 SIZE 6 "|Курган Алтайская Орехово Войновка Инская Бердяуш Смычка Агрыз Юдино Богданович Каменск-Уральский |" 2876 SIZE 11 "|Лянгасово Егоршино Пермь Омск Екатеринбург Нижний Новгород Челябинск |" 5161 SIZE 7 "|Курган Алтайская Орехово Войновка Инская Бердяуш Смычка Чусовская Агрыз Юдино Богданович Каменск-Уральский |" 5953 SIZE 12 "|Лянгасово Егоршино Орехово Пермь Войновка Инская Омск Екатеринбург Бердяуш Смычка Чусовская Агрыз Нижний Новгород Юдино Челябинск Богданович Каменск-Уральский Курган Алтайская |" 7984 SIZE 19 Что это значит?а вот что : SIZE - размер сформированного кластера, чилос перед SIZE - срез, на котором кластер сформирован, ну и соответственно его состав. Мой вопрос в том, что можно это как-либо оптимизировать?Допустим, что бы не проходил вершины, которые уже посчитал как еденичный кластер и т.д. Просто для параметра "Количество сортировочных путей" у меня считает не правильно кластера т.к там одинаковые ребра по весу.. Да к тому же , эта оптимизация мне нужная для того, что бы нормально отрисовывать дендрограмму ( как на сайте снизу), т.к я буду использовать "события" Qt(сигналы/слоты) что, кого поглотило и отрисовывать их по-порядку, а не после нахождения... Сообщение отредактировано: volvo - 30.11.2009 13:28 |
|
|
|
| volvo |
25.11.2009 0:38
Сообщение
#6
|
|
Гость |
Цитата А твои результаты я не понял. У меня в принципе то же самое вот до этого момента:Цитата У него на Срезе 15 обременяются вершины Инская и лянгасово, т.к между ними мин. ребро (я просто печатаю не всю таблицу, а только добавленную на определенном этапе вершину), то есть:на срезе 156 к этому ребру/кластеру добовляется вершина Орехово, т.к она связана с одной из вершин в предыдущем кластере(а именно - Инская) следующим мин. ребром с весом в 156..По тому же принципу и Егоршино на срезе 176 добавляется в тот же кластер, далее Омск на срезе 226, Пермь на срезе 239 (т.к все они имею связи через ребра МОД). Цитата Lantasovo : 0 Цитата Что-то ты нагромоздил кода А здесь моего-то кода - всего 30 строк, все остальное - то, что было у тебя и вывод результатов.Добавлено через 7 мин. Цитата всеравно без Qt не получиться скомпилировать Обижаешь... Qt как раз имеется. |
|
|
|
| Andrewshkovskii |
25.11.2009 0:52
Сообщение
#7
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
На 0 этапе добавил Лянгасово куда-то?Ну про код просто я сморозил глупость, надо поспать...
А ебург с войновкой соединяется потому что между ними ребром со следующим мин. весом, а потом к Ебургу и Войновке остальные кластера.. Смотри, вот ребра : Цитата "|Лянгасово Инская |" 15 "|Орехово Инская |" 156 "|Лянгасово Егоршино |" 177 "|Егоршино Омск |" 226 "|Пермь Омск |" 239 "|Войновка Екатеринбург |" 334 "|Пермь Войновка |" 339 Войновка соедененна с Екатеренбургом по 334 весу. После чего, ищем с каким кластером у нас есть пересечение Войновка и Екатеринбург , и находим его в 339 значении.. а т.к в вершине ПЕРМЬ давно у нас уже остальные вершины собраны..то получается поглащение.. Ну если Qt есть, то вот проект (4.5.2 версия) http://webfile.ru/4109074 Сообщение отредактировано: Andrewshkovskii - 25.11.2009 0:54 |
|
|
|
| volvo |
25.11.2009 13:04
Сообщение
#8
|
|
Гость |
Так... До Qt я вчера так и не добрался, сегодня вечером гляну... Вот чего придумалось обычным STL-ем:
 main.cpp ( 5.01 килобайт )
Кол-во скачиваний: 419
main.cpp ( 5.01 килобайт )
Кол-во скачиваний: 419(файл в кодировке Unicode) Вот вывод: Lantasovo Inskaya SREZ = 15 Так более понятно, чем было раньше? Причем в каждый момент времени (при push_back-е) уже известно, что на данном шаге сделано, либо новый кластер, либо присоединение вершины к кластеру, либо слияние двух кластеров... Какой ты там пример говорил у тебя не получается? Надо будет попробовать на нем прогнать этот алгоритм. |
|
|
|
| Andrewshkovskii |
25.11.2009 13:18
Сообщение
#9
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Да, результат более понятно,сейчас в коде по-разбираюсь.
Пример не получался с таких исходных данных : Цитата 0,2,6,5,3,6 2,0,4,3,1,4 6,4,0,1,3,0 5,3,1,0,2,1 3,1,3,2,0,3 6,4,0,1,3,0 Сейчас попробую прогнать. |
|
|
|
| Andrewshkovskii |
25.11.2009 14:41
Сообщение
#10
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Цитата 0 2 0 0 0 0 2 0 0 0 1 0 0 0 0 1 0 0 0 0 1 0 2 1 0 1 0 2 0 0 0 0 0 1 0 0 5 Egorshino Voynovka SREZ = 1 Orehovo Perm SREZ = 1 Orehovo Perm Inskaya SREZ = 1 Egorshino Voynovka Lantasovo SREZ = 2 Orehovo Perm Egorshino Voynovka SREZ = 2 Вот такой вот результат,из-за одинковых значений получается не правильно. Там, ещё, кстати, надо сравнивать на равенство, и равные по весу ребра/кластера тоже стаскивать. Вот результат по моему коду : Цитата Ребра "|Егоршино Войновка |" 1 "|Орехово Пермь |" 1 "|Пермь Инская |" 1 "|Пермь Войновка |" 2 "|Лянгасово Егоршино |" 2 //appended - какое ребро/кластер образовано от поглащения //single - ребро, которое и так есть кластер. В 5 сообщении видно когда эта информация выводиться.. appended "|Егоршино Пермь Войновка |" 2 appended "|Лянгасово Егоршино Войновка |" 2 appended "|Орехово Пермь Инская |" 1 appended "|Егоршино Орехово Пермь Войновка |" 2 appended "|Орехово Пермь Инская |" 1 appended "|Егоршино Орехово Пермь Войновка Инская |" 2 single "|Егоршино Орехово Пермь Войновка Инская |" 2 single "|Егоршино Орехово Пермь Войновка Инская |" 2 single "|Егоршино Орехово Пермь Войновка Инская |" 2 appended "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 single "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 single "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 single "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 appended "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 //результирующие ребра... 2 "|Егоршино Войновка |" 1 SIZE 2 2 "|Орехово Пермь Инская |" 1 SIZE 3 2 "|Орехово Пермь Инская |" 1 SIZE 3 2 "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 SIZE 6 2 "|Лянгасово Егоршино Орехово Пермь Войновка Инская |" 2 SIZE 6 Т.е. 2 раза одно и тоже ребро получается... |
|
|
|
| volvo |
26.11.2009 1:44
Сообщение
#11
|
|
Гость |
В общем, вот чего у меня получилось после полной переработки всего, что только можно было проверить и сделать:
 main.cpp ( 13.96 килобайт )
Кол-во скачиваний: 432
main.cpp ( 13.96 килобайт )
Кол-во скачиваний: 432(все тот же Unicode, там каждый чих логгируется, если не хочешь - закомментируй #define TEST, тебе сразу вывалит результаты). По-моему все правильно делается, проверь еще на всякий случай, у меня что-то уже аллергия на эту программу образовалась  |
|
|
|
| Andrewshkovskii |
26.11.2009 2:42
Сообщение
#12
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Мда, мне далекова-то до твоих мозгов, Владимир..Спасибо..
Считает, вроде бы, правильно. Ты не смотрел моё кутёвый пример?Просто может там используя qtstl не будет необходимости писать свои операторы пересечения и т.д.. А в коде попробую разобраться, ты не против, если я буду спрашивать?И ещё хотелось бы почитать вербальное(словестное) описание алгоритма, который ты придумал, может я тогда и сам дойду до того, что бы написать используя qtstl. Почему так много Qt? Ну не знаю, просто нравиться она мне, и её stl шикарный.. А вот что касается std::stl, то тут меня пробелы в знаниях, и немного тяжеловато.. |
|
|
|
| volvo |
26.11.2009 2:59
Сообщение
#13
|
|
Гость |
Цитата Просто может там используя qtstl не будет необходимости писать свои операторы пересечения и т.д.. Это вряд ли... В Qt очень сокращенная версия STL-я. Кстати, мой код можно раза в 4 сократить, если использовать готовые алгоритмы (типа copy_if/remove_if), я оставил без изменения, как есть, чтоб было проще разобраться.На самом деле алгоритм очень простой: С самого начала все вершины превращаем в кластеры, состоящие из одной-единственной вершины. Потом проходим по таблице МОД-а и для каждой вершины запихиваем в вектор Edges все вершины/стоимости, с которыми связана данная вершина. А потом просто проходим по всем кластерам, ищем в активных минимальное ребро. Нашли? Проверили, что связано это ребро тоже с активным кластером со второй стороны (вот на этом я потерял достаточно много времени, никак не мог сообразить, чего же не хватает)? Прекрасно, сливаем два кластера, для этого обновляем VX - список вершин, принадлежащих кластеру, и список Edges изменяем так, что все ссылки "друг на друга" просто убираются, остаются только ссылки на другие вершины, не принадлежащие в текущие момент данному кластеру. А вот потом делается то, что отняло у меня еще больше времени, чем проверка активности второго кластера. Вот этот кусок необходим перед тем, как задизейблить кластер, влитый в другой: // ***Я раньше не делал этого, у меня получался сплошной бред в итоге. Просто проходим по всем кластерам, и если где-то есть ссылка на "влитый", то меняем ее на ссылку на "увеличенный", в который вливали... Вот и все. Продолжать до Если хочешь - я завтра попробую покумекать над сокращением кода, хотя тебе ж для QT - тогда многое будет непереносимо. |
|
|
|
| volvo |
26.11.2009 18:41
Сообщение
#14
|
|
Гость |
Цитата Если хочешь - я завтра попробую покумекать над сокращением кода В первом приближении - вот так (тут очень многое делается через стандартные алгоритмы, а не циклами):
main.cpp ( 9.12 килобайт )
Кол-во скачиваний: 413 |
|
|
|
| Andrewshkovskii |
27.11.2009 0:04
Сообщение
#15
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Ох, только добрался до компа, весь день в институте просидел.. Так, сейчас скачаю и попробую разобраться.если что, надеюсь на твою благосклонность и отзывчивость (сможешь подтвердить или опровергнуть мои догадки насчет происходящих действий в коде:)
|
|
|
|
| Andrewshkovskii |
27.11.2009 13:44
Сообщение
#16
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Ну в общем я попробовал разобраться, все в исходнике (комментарии и вопросы), ещё одно хотелось бы понять точно :
Где именно у нас образуется/поглощается кластер в коде? Для чего : что бы можно было нарисовать дендрограмму кластеров. А для этого нужно ещё добавить в класс кластер , его координату на визуальном объекте отрисовки. Для отдельной вершины это будет координата Текстового значения , что бы можно было провести вот такое 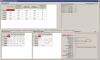 А для кластера, его центр (все изображено на рисунке). Т.е когда образуется кластер, или кластер поглошается, я буду вызывать сигнал, в котором буду передавать : 1. Кто поглотил 2. Кого поглотил У меня в проекте есть маппер, для каждой вершины и её текстового значения на отображении, т.е. таким образом я смогу нарисовать кластер от одной вершины к другой, зная какое событие произошло : то ли поглощение, то ли образование. Соответственно нужно разделение на :Создание кластера и поглощение кластера.. Прикрепленные файлы
main.cpp ( 9.12 килобайт )
Кол-во скачиваний: 206 |
|
|
|
| volvo |
27.11.2009 13:53
Сообщение
#17
|
|
Гость |
Цитата все в исходнике (комментарии и вопросы) Ты точно нужный исходник присоединил? А то по-моему это тот, что я приаттачивал в 14-м посте, буква в букву...Насчет кластеров - сливаются кластеры здесь: void MyCluster :: operator += (MyCluster& cL)Кто поглотил - this, кого поглотил - cL. Что касается создания - то можешь проверять длину vx, и если для обоих кластеров она = 1, то считай, что это раньше были 2 вершины, и они создали кластер. |
|
|
|
| Andrewshkovskii |
27.11.2009 13:55
Сообщение
#18
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Упс, исходник вот.
Насчет длины вектора так и думал:) Прикрепленные файлы
main.cpp ( 10.58 килобайт )
Кол-во скачиваний: 239 |
|
|
|
| volvo |
27.11.2009 14:55
Сообщение
#19
|
|
Гость |
Вот ответы:
(я оставил твои комментарии, ниже добавил свои /* вот такие */)
main.cpp ( 14.58 килобайт )
Кол-во скачиваний: 495 |
|
|
|
| Andrewshkovskii |
27.11.2009 17:10
Сообщение
#20
|
|
Бывалый Группа: Пользователи Сообщений: 222 Пол: Мужской Реальное имя: Andrew Репутация: 0 |
Так, слегка проникся кодом, и даже что-то понял:)
Только одна ситуация. Предположим, что у нас есть некая структура данных, которая содержит визуальные координаты вершин (ну, например, vector <map <int , pos> >, где pos - координата x,y).И соответственно есть поле у класса Cluster такого же типа, только оно содержит : 1. Если кластер из одной вершины - то визуальную координату вершины. 2. Если в кластере вершин > 1 , то уже содержит визуальный центр кластера. Предположим, что когда мы создаем кластер из одной вершины, и при создании координата вершины записывается в конструкторе. Далее, когда мы сливаем кластер, нам необходимо изменить координату центра, т.е. есть 2 кластера с одной вершиной(к1,к2) ,и кластер(из 1 вершины, но со значением sr > получившегося из образование к1 и к2 кластера) к3. Вот что получается... Цитата 1 шаг : к1 и к2 объединяются. Вызывается метод, который визуально это отображает : чертит из центра к1 в к2 "скобу" (можно увидеть на посте 16 что такое скоба) изменяем центр к1 на центр скобы. ВОПРОС : где удобнее будет вызывать этот метод отрисовки , в операторе += или после его выполнения? (Ведь к1 теперь станет кластером с 2мя вершинами, ну, имеется ввиду, что к1 это clusters[ii]. 2 шаг : К3 поглошает к1. Вызывается метод, который визуально это отображает из центра К3 чертит "скобу" в центр кластера к1. тоесть из центра clusters[ii] в центра clusters[jj], и изменяем центр К3 на центр новой "скобы" По твоему мнению, такая логика будет достаточно верной? |
|
|
|
|
1 чел. читают эту тему (гостей: 1, скрытых пользователей: 0)
Пользователей: 0

|
Текстовая версия | 22.07.2025 2:22 |