
 ПРАВИЛА РАЗДЕЛА!!!
ПРАВИЛА РАЗДЕЛА!!!
1. Заголовок или название темы должно быть информативным
2. Все тексты программ должны помещаться в теги [CODE=asm] [/CODE]
3. Прежде чем задавать вопрос, см. "FAQ",если там не нашли ответа, воспользуйтесь ПОИСКОМ, возможно, такую задачу уже решали!
4. Не предлагайте свои решения на других языках, кроме Ассемблера. Исключение только с согласия модератора.
5. НЕ используйте форум для личного общения! Все, что не относиться к обсуждению темы - на PM!
6. Проверяйте программы перед тем, как выложить их на форум!!
  |

| Hey |
 7.09.2012 20:32 7.09.2012 20:32
Сообщение
#1
|
|
Новичок  Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация:  0 0  |
Приветствую,
пишу программу вычисления интеграла функции 1/ln x методом трапеций, для начала взял n=20 (затем буду увеличивать). Файл .exe создан, но выдает ошибку и вылетает. При просмотре в дебаггере вижу, что еще на этапе вычисления шага в регистре ST0 оказывается отрицательная величина, еще через пару шагов вылетает. В чем тут дело? Заранее спасибо.
|
   |

 
|
| IUnknown |
8.09.2012 12:00
Сообщение
#2
|
 a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
А ты в дебаггере посмотрел, что именно грузится в ST0 при выполнении
finit? Там явно не 5-ка, а 8397: 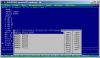 Измени режим процессора на .286p, тогда значения станут подгружаться нормально, и по крайней мере h вычисляется правильно, дальше не проверял. |
|
|
|
| Hey |
9.09.2012 12:30
Сообщение
#3
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Спасибо, с тем фрагментом действительно пошло. Где-то дальше еще есть ошибки, сейчас буду смотреть.
|
|
|
|
| TarasBer |
9.09.2012 14:31
Сообщение
#4
|
 Злостный любитель Группа: Пользователи Сообщений: 1 755 Пол: Мужской Репутация: 62 |
А почему всё-таки fild пятёрки загрузил 8397?
-------------------- |
|
|
|
| Hey |
9.09.2012 17:30
Сообщение
#5
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Снова загвоздка: не принимает директиву loop, попросту ее пропускает. Это свойство моей версии ассемблера или режима 286р?
P.S. Виноват: забыл на счетчик СХ поставить. Правда, он почему-то считает только два цикла, затем обнуляется. Притом во втором цикле в x грузит сразу 4,8 вместо 2,15. ... прилагаю новый листинг.
Сообщение отредактировано: Hey - 9.09.2012 18:29 |
|
|
|
| IUnknown |
9.09.2012 18:14
Сообщение
#6
|
|
a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
Цитата Это свойство моей версии ассемблера или режима 286р? Это особенности цикла LOOP. Чтобы он работал, надо занести число повторений в CX. У тебя CX - нулевой. Похоже, тебе нужен не LOOP, а простой JMP, если ты из цикла уходишь по "je mult_"Цитата А почему всё-таки fild пятёрки загрузил 8397? А кто его знает... В 286-ом режиме грузит нормально, выше - начинает придумывать что-то своё. |
|
|
|
| Hey |
9.09.2012 18:31
Сообщение
#7
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
P.S. ТОчно, забыл на счетчик СХ поставить. Правда, он почему-то считает только два цикла, затем обнуляется. Притом во втором цикле в x грузит сразу 4,8 вместо 2,15. ... прилагаю новый листинг.
.286p .model small .stack 100h .data a dw 2 b dw 5 x dq 2 n dw 20 h dq ? y dq ? .code main proc mov ax, @data mov ds, ax mov CX, [n] dec CX finit fild b fisub a fidiv n fst h ;вычисляем шаг h finit fld1 fild b fyl2x fldln2 fmul ; вычиcляем ln 5 fld1 fdivr ;вычиcляем 1/ln 5 fstp y fldln2 fld1 fdivr ; вычисляем 1/ln2 fadd y fstp y fild a fld y fdivr ;вычисляем (1/ln a + 1/ln b)/2 fstp y cycl: finit fld x fadd h fst x ;производим приращение х и каждый раз сохраняем fld1 fld x fyl2x fldln2 fmul fld1 ; fdivr ; fadd y fstp y loop cycl ; mult_: fld y fld h fmul |
|
|
|
| IUnknown |
9.09.2012 19:04
Сообщение
#8
|
|
a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
С описанием
x dd 2.0все итерации проходят (проверял 4 первых, дальше не хватило терпения, на выходе, после того как цикл завершился) имеем: Эскизы прикрепленных изображений 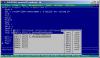
|
|
|
|
| Hey |
9.09.2012 21:08
Сообщение
#9
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Цитата(IUnknown @ 9.09.2012 20:04)  С описанием x dd 2.0все итерации проходят (проверял 4 первых, дальше не хватило терпения, на выходе, после того как цикл завершился) имеем: Отлично, спасибо! Теперь начну увеличивать n, пока не достигну требуемой точности. |
|
|
|
| Hey |
10.09.2012 16:48
Сообщение
#10
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Опять вынужден обратиться: программу продолжил, но новый фрагмент он не видит и сразу переходит к выводу на экран прежнего значения для n=20. Привожу листинг без процедуры вывода на экран:
|
|
|
|
| IUnknown |
10.09.2012 20:12
Сообщение
#11
|
|
a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
Во-первых, с чего ты решил, что вот это:
Цитата fild n fcomp x ; сравниваем верхушку стека с числом XА во-вторых - зачем тебе все эти пляски с прыжками из одной части кода в другую? Сделай 2 нормальных вложенных цикла, изначально N присвой 0, и тут же его увеличивай на D, это будет внешний цикл. А внутренний - вычисление самого интеграла. Программа упростится донельзя (а если еще воспользоваться макросредствами ассемблера - у тебя же TASM, я правильно понимаю?) то все будет еще проще. |
|
|
|
| IUnknown |
11.09.2012 16:14
Сообщение
#12
|
|
a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
Вот первоначальный вариант (можно еще дорабатывать)
.286p |
|
|
|
| Hey |
11.09.2012 21:54
Сообщение
#13
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Однако серьезно! Буду пробовать. Признателен)
Кстати, почему я организовал дополнительные циклы, и ввел переменную у2: необходимо найти решение с определенной точностью (0,0001). Для этого придется сравнивать значения F для каждых "соседних" n. Соответственно, если для каждого последующего n я записываю значения f в одну и ту же переменную у, то значения при меньшем n теряются. Попробую что-нибудь придумать. Сообщение отредактировано: Hey - 11.09.2012 22:54 |
|
|
|
| Hey |
12.09.2012 18:11
Сообщение
#14
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Цикл ему кажется слишком длинным: на инструкции loop outer_loop выдает "Relative jump out of range by 22h bytes". И почему-то стал ругаться на невинную команду fstsw ax: "Illegal immediate".
P.S. Я решил оформить макросом приращение n и вычисление h, прилагаю код целиком.
|
|
|
|
| IUnknown |
12.09.2012 23:10
Сообщение
#15
|
|
a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
Цитата Цикл ему кажется слишком длинным: на инструкции loop outer_loop выдает "Relative jump out of range by 22h bytes". И почему-то стал ругаться на невинную команду fstsw ax: "Illegal immediate". Ты б за структурой следил, и вторую процедуру записывал бы после того, как первая закончится - было бы меньше неожиданностей. Насчет цикла - не подтверждается, код прекрасно собирается (помнят еще руки-то  Цикл рассчитан до байта, добавляем еще одну инструкцию - 2 лишних байта для LOOP-а). На скрине - результат компиляции и запуска вот такого кода: Цикл рассчитан до байта, добавляем еще одну инструкцию - 2 лишних байта для LOOP-а). На скрине - результат компиляции и запуска вот такого кода:.286p Сообщение отредактировано: IUnknown - 12.09.2012 23:11 Эскизы прикрепленных изображений 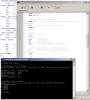
|
|
|
|
| Hey |
13.09.2012 14:32
Сообщение
#16
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Да, фрагмент с exit'ом я не туда вставил. Действительно работает, спасибо)). Вопрос: что означает строка NL db 0Dh, 0Ah, "$" ?
|
|
|
|
| IUnknown |
13.09.2012 15:09
Сообщение
#17
|
|
a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
Это для перевода строки: NewLine, символ CR = 13, символ LF = 10, и завершение строки - знак доллара
|
|
|
|
| Hey |
14.09.2012 20:22
Сообщение
#18
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
Решительно не хватает знаний, чтобы успешно завершить программу. Я ее расширил, чтобы n возрастало до тех пор, пока не будет достигнута требуемая точность (0.0001). Вместо вывода значения функции при каждом из n (20, 40, 60 ....) прога выводит окончательное значение, причем не один раз((. Вывод n также не работает. Прилагаю.
|
|
|
|
| IUnknown |
15.09.2012 11:30
Сообщение
#19
|
|
a.k.a. volvo877 Группа: Пользователи Сообщений: 1 013 Пол: Мужской Репутация: 627 |
Hey, я опять не понял, зачем тебе 2 цикла, в каждом из которых ты вычисляешь значения интегралов? Давай запишем алгоритм который тебе нужен, в псевдокоде. Итак, чтобы определить, при каком N значение интеграла найдено с точностью Eps, тебе достаточно:
n <- 0 Всё, никаких двойных циклов, все прекрасно делается одним. А теперь смотри, как это записывается на ассемблере (я заменил переменную z на prev): main procПроще, правда, чем делать дважды одно и то же? Теперь насчет Цитата Вывод n также не работает. Процедуру OutInt проверять не пробовал? Вообще-то, она должна выглядеть так (вообще-то, жестко задавать в программе, что процедура выводит именно N - это бред, лучше перед ее вызовом занести ax <- N): outint proc nearС этими изменениями программа прекрасно отрабатывает: F:\Asm30>trapece |
|
|
|
| Hey |
15.09.2012 17:36
Сообщение
#20
|
|
Новичок Группа: Пользователи Сообщений: 15 Пол: Мужской Репутация: 0 |
IUnknown, ты прав: уперся я в свое решение как лунатик и увидеть больше ничего не мог). С одним циклом все внятно. Спасибо за терпение
. Еще вопрос: в какой программе ты набираешь листинг? Явно не блокнот. |
|
|
|
|
5 чел. читают эту тему (гостей: 5, скрытых пользователей: 0)
Пользователей: 0

|
Текстовая версия | 19.02.2025 2:00 |