Версия для печати темы
Нажмите сюда для просмотра этой темы в обычном формате
Форум «Всё о Паскале» _ Assembler _ Ошибка в программе вычисления интеграла
Автор: Hey 7.09.2012 20:32
Приветствую,
пишу программу вычисления интеграла функции 1/ln x методом трапеций, для начала взял n=20 (затем буду увеличивать). Файл .exe создан, но выдает ошибку и вылетает. При просмотре в дебаггере вижу, что еще на этапе вычисления шага в регистре ST0 оказывается отрицательная величина, еще через пару шагов вылетает. В чем тут дело?
Заранее спасибо.
.486p
.model small
.stack 100h
.data
a dw 2
b dw 5
x dq 2
n dw 20
h dq ?
y dq ?
.code
main proc
mov ax, @data
mov ds, ax
finit
fild b
fisub a
fidiv n
fst h ;вычисляем шаг h
fld1
fild b
fyl2x
fldln2
fmul
fld1
fdiv
fADD y
fild b
fdivr st(1), st ;вычисляем (ln a + ln b)/2
cycl:
fadd y
fst y
fild x
fadd h
fst x ;производим приращение х и каждый раз сохраняем
ficom b
je mult_ ;пока не равно b(=5),продолжаем
fld x
fyl2x
fldln2
fmul
fld1
fdiv ;
loop cycl ;
mult_:
fld y ;
fld h ;
fmul ;когда х достиг значения 5, перемножаем на h
exit:
mov ax, 4c00h ;
int 21h ;
main endp
end main
Автор: IUnknown 8.09.2012 12:00
А ты в дебаггере посмотрел, что именно грузится в ST0 при выполнении
finit? Там явно не 5-ка, а 8397:
fild b ; <--- вот этой строки
fisub a
fidiv n
fst h ;вычисляем шаг h
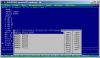
Измени режим процессора на .286p, тогда значения станут подгружаться нормально, и по крайней мере h вычисляется правильно, дальше не проверял.
Автор: Hey 9.09.2012 12:30
Спасибо, с тем фрагментом действительно пошло. Где-то дальше еще есть ошибки, сейчас буду смотреть.
Автор: TarasBer 9.09.2012 14:31
А почему всё-таки fild пятёрки загрузил 8397?
Автор: Hey 9.09.2012 17:30
Снова загвоздка: не принимает директиву loop, попросту ее пропускает. Это свойство моей версии ассемблера или режима 286р?
P.S. Виноват: забыл на счетчик СХ поставить. Правда, он почему-то считает только два цикла, затем обнуляется. Притом во втором цикле в x грузит сразу 4,8 вместо 2,15. ... прилагаю новый листинг.
.286p
.model small
.stack 100h
.data
a dw 2
b dw 5
x dq 2
n dw 20
h dq ?
y dq ?
.code
main proc
mov ax, @data
mov ds, ax
mov CX, [n]
dec CX
finit
fild b
fisub a
fidiv n
fst h ;вычисляем шаг h
finit
fld1
fild b
fyl2x
fldln2
fmul ; вычиcляем ln 5
fld1
fdivr ;вычиcляем 1/ln 5
fstp y
fldln2
fld1
fdivr ; вычисляем 1/ln2
fadd y
fstp y
fild a
fld y
fdivr ;вычисляем (1/ln a + 1/ln b)/2
fstp y
cycl:
finit
fld x
fadd h
fst x ;производим приращение х и каждый раз сохраняем
fld1
fld x
fyl2x
fldln2
fmul
fld1 ;
fdivr ;
fadd y
fstp y
loop cycl ;
mult_:
fld y
fld h
fmul ;когда х достиг значения 5, перемножаем на h
Автор: IUnknown 9.09.2012 18:14
Автор: Hey 9.09.2012 18:31
P.S. ТОчно, забыл на счетчик СХ поставить. Правда, он почему-то считает только два цикла, затем обнуляется. Притом во втором цикле в x грузит сразу 4,8 вместо 2,15. ... прилагаю новый листинг.
.286p
.model small
.stack 100h
.data
a dw 2
b dw 5
x dq 2
n dw 20
h dq ?
y dq ?
.code
main proc
mov ax, @data
mov ds, ax
mov CX, [n]
dec CX
finit
fild b
fisub a
fidiv n
fst h ;вычисляем шаг h
finit
fld1
fild b
fyl2x
fldln2
fmul ; вычиcляем ln 5
fld1
fdivr ;вычиcляем 1/ln 5
fstp y
fldln2
fld1
fdivr ; вычисляем 1/ln2
fadd y
fstp y
fild a
fld y
fdivr ;вычисляем (1/ln a + 1/ln b)/2
fstp y
cycl:
finit
fld x
fadd h
fst x ;производим приращение х и каждый раз сохраняем
fld1
fld x
fyl2x
fldln2
fmul
fld1 ;
fdivr ;
fadd y
fstp y
loop cycl ;
mult_:
fld y
fld h
fmul
Автор: IUnknown 9.09.2012 19:04
С описанием
x dd 2.0все итерации проходят (проверял 4 первых, дальше не хватило терпения, на выходе, после того как цикл завершился) имеем:
Эскизы прикрепленных изображений
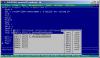
Автор: Hey 9.09.2012 21:08

С описанием
x dd 2.0все итерации проходят (проверял 4 первых, дальше не хватило терпения, на выходе, после того как цикл завершился) имеем:
Отлично, спасибо! Теперь начну увеличивать n, пока не достигну требуемой точности.
Автор: Hey 10.09.2012 16:48
Опять вынужден обратиться: программу продолжил, но новый фрагмент он не видит и сразу переходит к выводу на экран прежнего значения для n=20. Привожу листинг без процедуры вывода на экран:
.286p
.model small
.stack 100h
.data
a dw 2
b dw 5
x dd 2.0
n dw 20
d dw 20
h dq ?
y dq ?
y2 dq ?
.code
main proc
mov ax, @data
mov ds, ax
m1: mov CX, [n]
dec CX
finit
fild b
fisub a
fidiv n
fst h ;вычисляем шаг h
finit
fld1
fild b
fyl2x
fldln2
fmul ; вычиcляем ln 5
fld1
fdivr ;вычиcляем 1/ln 5
fild n
ficom d
jg m2
fxch
fstp y
fldln2
fld1
fdivr ; вычисляем 1/ln2
fadd y
fstp y
fild a
fld y
fdivr ;вычисляем (1/ln a + 1/ln b)/2
fstp y
cycl:
finit
fld x
fadd h
fst x ;производим приращение х и каждый раз
сохраняем
fld1
fld x
fyl2x
fldln2
fmul
fld1 ;
fdivr ;
fadd y
fstp y
loop cycl
mult_:
fld y
fld h
fmul ;когда х = 5, перемножаем на h
fst y
;повторяем то же для n=40
finit
fild n
fiadd d
fistp n
jmp m1
m2:
fxch
fstp y2
fldln2
fld1
fdivr ; вычисляем 1/ln2
fadd y2
fstp y2
fild a
fld y2
fdivr ;вычисляем (1/ln a + 1/ln b)/2
fstp y2
cycl2:
finit
fld x
fadd h
fst x ;производим приращение х и каждый раз
сохраняем
fld1
fld x
fyl2x
fldln2
fmul
fld1 ;
fdivr ;
fadd y2
fstp y2
loop cycl2 ;
mult2_:
fld y2
fld h
fmul ;61 когда х = 5, перемножаем на h
fst y2
fsub y
fabs
Автор: IUnknown 10.09.2012 20:12
Во-первых, с чего ты решил, что вот это:
fild n
ficom d
jg m2
fcomp x ; сравниваем верхушку стека с числом XА во-вторых - зачем тебе все эти пляски с прыжками из одной части кода в другую? Сделай 2 нормальных вложенных цикла, изначально N присвой 0, и тут же его увеличивай на D, это будет внешний цикл. А внутренний - вычисление самого интеграла. Программа упростится донельзя (а если еще воспользоваться макросредствами ассемблера - у тебя же TASM, я правильно понимаю?) то все будет еще проще.
fstsw ax ; сохраняем слово состояния сопроцессора в AX
sahf ; заталкиваем AH в регистр флагов
; а теперь - внимание:
jp lbl_1 ; значения несравнимы
jc lbl_2 ; st(0) < x
jz lbl_3 ; st(0) = x
; Раз мы пришли сюда - значит st(0) > x
Автор: IUnknown 11.09.2012 16:14
Вот первоначальный вариант (можно еще дорабатывать)
.286p
.model small
.stack 100h
.data
a dw 2
b dw 5
x dq 2.0
n dw 0
d dw 20
h dq ?
y dq ?
.code
CalcF macro ; На вершине стека должен быть параметр
fld1
fld st(1)
fyl2x
fldln2
fmul
fld1
fdivr
endm
iCalcF macro param
fld1
fild param
fyl2x
fldln2
fmul
fld1
fdivr
endm
main proc
mov ax, @data
mov ds, ax
; начинаем цикл по увеличению N
mov cx, 3 ; Будут рассчитаны значения при N = 20, 40, 60
outer_loop:
push cx
mov cx, n
add cx, d
mov n, cx
dec cx
; вычисляем шаг
finit
fild b
fisub a
fidiv n
fst h ; Сохраняем шаг
iCalcF b ; 1 / ln b
fstp y
iCalcF a ; 1 / ln a
fadd y ; Складываем
fdiv x ; Делим сумму на 2
fstp y ; Сохраняем начальное приближение
; Теперь внутренний цикл - вычисляем интеграл
fld x ; Будем держать X в стеке сопроцессора
inner_loop:
fadd h ; X <- X + h
CalcF
fadd y
fstp y ; Сохраняем измененное значение интеграла
loop inner_loop
fld y
fmul h ; Домножаем на h - получаем искомое значение
call outfloat
pop cx
loop outer_loop;
exit:
mov ax, 4c00h ;
int 21h ;
main endp
; За кадром - реализация outfloat, распечатывающая содержимое
; вершины стека сопроцессора и выбрасывающая распечатанное
; значение из стека
Автор: Hey 11.09.2012 21:54
Однако серьезно! Буду пробовать. Признателен)
Кстати, почему я организовал дополнительные циклы, и ввел переменную у2: необходимо найти решение с определенной точностью (0,0001). Для этого придется сравнивать значения F для каждых "соседних" n. Соответственно, если для каждого последующего n я записываю значения f в одну и ту же переменную у, то значения при меньшем n теряются. Попробую что-нибудь придумать.
Автор: Hey 12.09.2012 18:11
Цикл ему кажется слишком длинным: на инструкции loop outer_loop выдает "Relative jump out of range by 22h bytes". И почему-то стал ругаться на невинную команду fstsw ax: "Illegal immediate".
P.S. Я решил оформить макросом приращение n и вычисление h, прилагаю код целиком.
.model small
.stack 100h
.data
a dw 2
b dw 5
x dq 2.0
n dw 0
d dw 20
h dq ?
y dq ?
.code
CalcF macro; На вершине стека д.б. параметр
fld1
fld st(1)
fyl2x
fldln2
fmul
fld1
fdivr
endm
iCalcF macro param
fld1
fild param
fyl2x
fldln2
fmul
fld1
fdivr
endm
calc_h macro
mov cx, n
add cx, d
mov n, cx
dec cx
; вычисляем шаг
finit
fild b
fisub a
fidiv n
fst h ; Сохраняем шаг
endm
main proc
mov ax, @data
mov ds, ax
; начинаем цикл по увеличению N
mov cx, 3 ; Будут рассчитаны значения при N = 20, 40, 60
outer_loop:
push cx
calc_h
iCalcF b ; 1 / ln b
fstp y
iCalcF a ; 1 / ln a
fadd y ; Складываем
fdiv x ; Делим сумму на 2
fstp y ; Сохр. начальное приближение
; Теперь внутренний цикл - вычисляем интеграл
fld x ; X в стек сопроцессора
inner_loop:
fadd h ; X <- X + h
CalcF
fadd y
fstp y ; Сохраняем измененное значение интеграла
loop inner_loop
fld y
fmul h
call outfloat
pop cx
loop outer_loop;
outfloat proc near ;вывод числа
push ax
push cx
push dx
push bp
mov bp, sp
push 10
push 0
; Проверяем число на знак, и если оно отрицательное,
ftst
fstsw ax
sahf
jnc @of1
; то выводим минус
mov ah, 02h
mov dl, '-'
int 21h
; и оставляем модуль числа.
fchs
@of1: fld1
fld st(1)
fprem
fsub st(2), st
fxch st(2)
xor cx, cx
@of2: fidiv word ptr [bp - 2]
fxch st(1)
fld st(1)
fprem
fsub st(2), st
fimul word ptr [bp - 2]
fistp word ptr [bp - 4]
inc cx
push word ptr [bp - 4]
fxch st(1)
ftst
fstsw ax
sahf
jnz short @of2
; Теперь выведем её.
mov ah, 02h
@of3: pop dx
add dl, 30h
int 21h
; И так, пока не выведем все цифры.
loop @of3
; Теперь за дробную часть, для начала ;проверив её существование.
fstp st(0)
fxch st(1)
ftst
fstsw ax
sahf
jz short @of5
; Если она ненулевая, выведем точку
mov ah, 02h
mov dl, '.'
int 21h
; и не более четырех цифр дробной части.
mov cx, 4
; Помножим дробную часть на десять,
@of4: fimul word ptr [bp - 2]
fxch st(1)
fld st(1)
; отделим целую часть
fprem
; оставим от произведения лишь дробную часть,
fsub st(2), st
fxch st(2)
; сохраним полученную цифру во временной ячейке
fistp word ptr [bp - 4]
; и сразу выведем.
mov ah, 02h
mov dl, [bp - 4]
add dl, 30h
int 21h
; Теперь, если остаток дробной части ненулевой
fxch st(1)
ftst
fstsw ax
sahf
; и мы вывели менее четырех цифр, продолжим.
loopnz @of4
; число выведено. Осталось убрать мусор из стэка.
@of5: fstp st(0)
fstp st(0)
; Точнее, стэков.
pop dx
pop cx
pop ax
ret
outfloat endp
exit:
mov ax, 4c00h ;
int 21h ;
main endp
Автор: IUnknown 12.09.2012 23:10
 Цикл рассчитан до байта, добавляем еще одну инструкцию - 2 лишних байта для LOOP-а). На скрине - результат компиляции и запуска вот такого кода:
Цикл рассчитан до байта, добавляем еще одну инструкцию - 2 лишних байта для LOOP-а). На скрине - результат компиляции и запуска вот такого кода:.286p
.model small
.stack 100h
.data
a dw 2
b dw 5
x dq 2.0
n dw 0
d dw 20
h dq ?
y dq ?
NL db 0Dh, 0Ah, "$"
.code
CalcF macro ; На вершине стека должен быть параметр
fld1
fld st(1)
fyl2x
fldln2
fmul
fld1
fdivr
endm
iCalcF macro param
fld1
fild param
fyl2x
fldln2
fmul
fld1
fdivr
endm
CalcH macro
mov cx, n
add cx, d
mov n, cx
dec cx
; вычисляем шаг
fild b
fisub a
fidiv n
fst h ; Сохраняем шаг
endm
main proc
mov ax, @data
mov ds, ax
; начинаем цикл по увеличению N
mov cx, 3 ; Будут рассчитаны значения при N = 20, 40, 60
outer_loop:
finit ; выносим инициализацию сюда
push cx
CalcH
iCalcF b ; 1 / ln b
fstp y
iCalcF a ; 1 / ln a
fadd y ; Складываем
fdiv x ; Делим сумму на 2
fstp y ; Сохраняем начальное приближение
; Теперь внутренний цикл - вычисляем интеграл
fld x ; Будем держать X в стеке сопроцессора
inner_loop:
fadd h ; X <- X + h
CalcF
fadd y
fstp y ; Сохраняем измененное значение интеграла
loop inner_loop
fld y
fmul h ; Домножаем на h - получаем искомое значение
call outfloat
pop cx
loop outer_loop;
exit:
mov ax, 4c00h ;
int 21h ;
main endp
; Требуется директива .286C или выше.
outfloat proc near
push ax
push cx
push dx
; Формируем кадр стэка, чтобы хранить в нём десятку
; и ещё какую-нибудь цифру.
push bp
mov bp, sp
push 10
push 0
; Проверяем число на знак, и если оно отрицательное,
ftst
fstsw ax
sahf
jnc @of1
; то выводим минус
mov ah, 02h
mov dl, '-'
int 21h
; и оставляем модуль числа.
fchs
; Пояснение далее пойдёт на примере. ; ST(0) ST(1) ST(2) ST(3) ...
; Отделим целую часть от дробной. ; 73.25 ... что-то не наше
@of1: fld1 ; 1 73.25 ...
fld st(1) ; 73.25 1 73.25 ...
; Остаток от деления на единицу даст дробную часть.
fprem ; 0.25 1 73.25 ...
; Если вычесть её из исходного числа, получится целая часть.
fsub st(2), st ; 0.25 1 73 ...
fxch st(2) ; 73 1 0.25 ...
; Сначала поработаем с целой частью. Считать количество цифр будем в CX.
xor cx, cx
; Поделим целую часть на десять,
@of2: fidiv word ptr [bp - 2] ; 7.3 1 0.25 ...
fxch st(1) ; 1 7.3 0.25 ...
fld st(1) ; 7.3 1 7.3 0.25 ...
; отделим дробную часть - очередную справа цифру целой части исходного числа,-
fprem ; 0.3 1 7.3 0.25 ...
; от чатсного оставим только целую часть
fsub st(2), st ; 0.3 1 7 0.25 ...
; и сохраним цифру
fimul word ptr [bp - 2] ; 3 1 7 0.25 ...
fistp word ptr [bp - 4] ; 1 7 0.25 ...
inc cx
; в стэке.
push word ptr [bp - 4]
fxch st(1) ; 7 1 0.25 ...
; Так будем повторять, пока от целой части не останется ноль.
ftst
fstsw ax
sahf
jnz short @of2
; Теперь выведем её.
mov ah, 02h
@of3: pop dx
; Вытаскиваем очередную цифру, переводим её в символ и выводим.
add dl, 30h
int 21h
; И так, пока не выведем все цифры.
loop @of3 ; 0 1 0.25 ...
; Итак, теперь возьмёмся за дробную часть, для начала проверив её существование.
fstp st(0) ; 1 0.25 ...
fxch st(1) ; 0.25 1 ...
ftst
fstsw ax
sahf
jz short @of5
; Если она всё-таки ненулевая, выведем точку
mov ah, 02h
mov dl, '.'
int 21h
; и не более шести цифр дробной части.
mov cx, 6
; Помножим дрообную часть на десять,
@of4: fimul word ptr [bp - 2] ; 2.5 1 ...
fxch st(1) ; 1 2.5 ...
fld st(1) ; 2.5 1 2.5 ...
; отделим целую часть - очередную слева цифру дробной части исходного числа,-
fprem ; 0.5 1 2.5 ...
; оставим от произведения лишь дробную часть,
fsub st(2), st ; 0.5 1 2 ...
fxch st(2) ; 2 1 0.5 ...
; сохраним полученную цифру во временной ячейке
fistp word ptr [bp - 4] ; 1 0.5 ...
; и сразу выведем.
mov ah, 02h
mov dl, [bp - 4]
add dl, 30h
int 21h
; Теперь, если остаток дробной части ненулевой
fxch st(1) ; 0.5 1 ...
ftst
fstsw ax
sahf
; и мы вывели менее шести цифр, продолжим.
loopnz @of4 ; 0 1 ...
; Итак, число выведено. Осталось убрать мусор из стэка.
@of5: fstp st(0) ; 1 ...
fstp st(0) ; ...
; Точнее, стэков.
leave
mov ah, 9
mov dx, offset NL
int 21h
pop dx
pop cx
pop ax
ret
outfloat endp
end main
Эскизы прикрепленных изображений
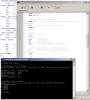
Автор: Hey 13.09.2012 14:32
Да, фрагмент с exit'ом я не туда вставил. Действительно работает, спасибо)). Вопрос: что означает строка NL db 0Dh, 0Ah, "$" ?
Автор: IUnknown 13.09.2012 15:09
Это для перевода строки: NewLine, символ CR = 13, символ LF = 10, и завершение строки - знак доллара
Автор: Hey 14.09.2012 20:22
Решительно не хватает знаний, чтобы успешно завершить программу. Я ее расширил, чтобы n возрастало до тех пор, пока не будет достигнута требуемая точность (0.0001). Вместо вывода значения функции при каждом из n (20, 40, 60 ....) прога выводит окончательное значение, причем не один раз((. Вывод n также не работает. Прилагаю.
.286p
.model small
.stack 100h
.data
mes db 'Operands not comparable', 13, 10, '$'
a dw 2
b dw 5
x dq 2.0
n dw 0
d dw 20
eps dd 0.0001
h dq ?
y dq ?
z dq ?
NL db 0Dh, 0Ah, "$"
.code
CalcF macro; На вершине стека д.б. параметр
fld1
fld st(1)
fyl2x
fldln2
fmul
fld1
fdivr
endm
iCalcF macro param
fld1
fild param
fyl2x
fldln2
fmul
fld1
fdivr
endm
Сalc_h macro
mov cx, n
add cx, d
mov n, cx
dec cx
; вычисляем шаг
finit
fild b
fisub a
fidiv n
fst h ; Сохраняем шаг
endm
main proc
mov ax, @data
mov ds, ax
outer_:
Сalc_h
iCalcF b ; 1 / ln b
fstp y
iCalcF a ; 1 / ln a
fadd y ; Складываем
fdiv x ; Делим сумму на 2
fstp y ; Сохр. начальное
приближение
; внутренний цикл - вычисляем
интеграл
fld x ; X в стек сопроцессора
inner_loop:
fadd h ; X <- X + h
CalcF
fadd y
fstp y ; Сохраняем измененное
значение интеграла
loop inner_loop
fld y
fmul h
call outfloat
call OutInt ;выводим актуальное n
finit
; далее повторяем с начала, но сохраняем в z для последующего сравнения с y
Сalc_h
iCalcF b ; 1 / ln b
fstp z
iCalcF a ; 1 / ln a
fadd z ; Складываем
fdiv x ; Делим сумму на 2
fstp z ; Сохр. начальное приближение
fld x ;
lesser_loop:
fadd h ; X <- X + h
CalcF
fadd z
fstp z ; Сохраняем измененное значение интеграла
loop lesser_loop
fld z
fmul h
call outfloat
call OutInt ;выводим актуальное n
fld z
fsub y
fabs
fcomp eps
fstsw ax
sahf
jp m2
jz m1
jc exit
jmp outer_
m1: jmp outer_
m2:
MOV DX, offset mes
mov Ah,09
int 21h
exit:
mov ax, 4c00h ;
int 21h ;
main endp
OutInt proc near
xor ax,ax
mov ax,n
xor cx, cx
mov bx, 10
l1:
xor dx,dx
div bx
push dx
inc cx
test ax, ax
jnz l1
mov ah, 02h
l2:
pop dx
loop l2
mov AH,9
mov dx, offset NL
int 21h
ret
outint endp
outfloat proc near ;вывод числа
push ax
push cx
push dx
push bp
mov bp, sp
push 10
push 0
; Проверяем число на знак, и если оно
отрицательное,
ftst
fstsw ax
sahf
jnc @of1
; то выводим минус
mov ah, 02h
mov dl, '-'
int 21h
; и оставляем модуль числа.
fchs
@of1: fld1
fld st(1)
fprem
fsub st(2), st
fxch st(2)
xor cx, cx
@of2: fidiv word ptr [bp - 2]
fxch st(1)
fld st(1)
fprem
fsub st(2), st
fimul word ptr [bp - 2]
fistp word ptr [bp - 4]
inc cx
push word ptr [bp - 4]
fxch st(1)
ftst
fstsw ax
sahf
jnz short @of2
; Теперь выведем её.
mov ah, 02h
@of3: pop dx
add dl, 30h
int 21h
; И так, пока не выведем все цифры.
loop @of3
; Теперь за дробную часть, для начала
;проверив её существование.
fstp st(0)
fxch st(1)
ftst
fstsw ax
sahf
jz short @of5
; Если она ненулевая, выведем точку
mov ah, 02h
mov dl, '.'
int 21h
; и не более четырех цифр дробной части.
mov cx, 4
; Помножим дробную часть на десять,
@of4: fimul word ptr [bp - 2]
fxch st(1)
fld st(1)
; отделим целую часть
fprem
; оставим от произведения лишь дробную
часть,
fsub st(2), st
fxch st(2)
; сохраним полученную цифру во временной
ячейке
fistp word ptr [bp - 4]
; и сразу выведем.
mov ah, 02h
mov dl, [bp - 4]
add dl, 30h
int 21h
; Теперь, если остаток дробной части
ненулевой
fxch st(1)
ftst
fstsw ax
sahf
; и мы вывели менее четырех цифр, продолжим.
loopnz @of4
; число выведено. Осталось убрать мусор из
стэка.
@of5: fstp st(0)
fstp st(0)
leave
mov AH,9
mov dx, offset NL
int 21h
pop dx
pop cx
pop ax
ret
outfloat endp
end main
Автор: IUnknown 15.09.2012 11:30
Hey, я опять не понял, зачем тебе 2 цикла, в каждом из которых ты вычисляешь значения интегралов? Давай запишем алгоритм который тебе нужен, в псевдокоде. Итак, чтобы определить, при каком N значение интеграла найдено с точностью Eps, тебе достаточно:
n <- 0
y <- 0.0;
repeat
prev <- y;
n <- n + DeltaN;
y <- Integral(a, b, n);
until abs(y - z) < eps;
print "finally Int = ", y, " when n = ", n
Всё, никаких двойных циклов, все прекрасно делается одним. А теперь смотри, как это записывается на ассемблере (я заменил переменную z на prev):
main procПроще, правда, чем делать дважды одно и то же?
mov ax, @data
mov ds, ax
outer_:
fld y
fstp prev
; fldz
; fstp y
; вычисляем шаг для текущего N
Сalc_h
iCalcF b ; 1 / ln b
fstp y
iCalcF a ; 1 / ln a
fadd y ; Складываем
fdiv x ; Делим сумму на 2
fstp y ; Сохр. начальное приближение
; внутренний цикл - вычисляем интеграл
fld x ; X в стек сопроцессора
inner_loop:
fadd h ; X <- X + h
CalcF ; F(X)
fadd y
fstp y ; Сохраняем измененное значение интеграла
loop inner_loop
fld y
fmul h ; нашли окончательное значение при текущем N
fst y ; сохранили его назад в Y для последующего сравнения с prev
; дублируем значение с вершины стека
; fld st
; выводим значение интеграла и N
call outfloat
call OutInt ; выводим актуальное n
fld y
fsub prev
fabs
fcomp eps
fstsw ax
sahf
jp uncomp
jz m1
jc exit
m1:
jmp outer_
uncomp:
mov dx, offset mes
mov ah, 09
int 21h
exit:
mov ax, 4c00h ;
int 21h ;
main endp
Теперь насчет
Вообще-то, она должна выглядеть так (вообще-то, жестко задавать в программе, что процедура выводит именно N - это бред, лучше перед ее вызовом занести ax <- N):
outint proc nearС этими изменениями программа прекрасно отрабатывает:
push cx
push dx
push bx
push ax
mov ax, n ; <--- !!! А этого лучше не делать !!!
; Проверяем число на знак.
test ax, ax
jns short @oi1
; Если оно отрицательное, выведем минус и оставим его модуль.
mov ah, 02h
mov dl, '-'
int 21h
pop ax
push ax
neg ax
; Количество цифр будем держать в CX.
@oi1: xor cx, cx
mov bx, 10
@oi2: xor dx, dx
div bx
; Делим число на десять. В остатке получается последняя цифра.
; Сразу выводить её нельзя, поэтому сохраним её в стэке.
push dx
inc cx
; А с частным повторяем то же самое, отделяя от него очередную
; цифру справа, пока не останется ноль, что значит, что дальше
; слева только нули.
test ax, ax
jnz short @oi2
; Теперь приступим к выводу.
mov ah, 02h
@oi3: pop dx
; Извлекаем очередную цифру, переводим её в символ и выводим.
add dl, 30h
int 21h
; Повторим ровно столько раз, сколько цифр насчитали.
loop @oi3
; переводим строку после выведенного числа
mov ah, 9
mov dx, offset NL
int 21h
pop ax
pop bx
pop dx
pop cx
ret
outint endp
F:\Asm30>trapece
2.5912
20
2.5898
40
2.5896
60
2.5895
80
F:\Asm30>
Автор: Hey 15.09.2012 17:36
IUnknown, ты прав: уперся я в свое решение как лунатик и увидеть больше ничего не мог). С одним циклом все внятно. Спасибо за терпение. Еще вопрос: в какой программе ты набираешь листинг? Явно не блокнот.
Автор: IUnknown 15.09.2012 18:24
Я использую http://www.scintilla.org/SciTEDownload.html, на движке Scintilla.Автор: Hey 15.09.2012 19:12
Отлично, спасибо))
Автор: Hey 5.10.2012 22:47
IUnknown, опять вынужден обратиться. Та же многострадальная программа, но для другой функции: требуется вычислить интеграл от функции sin (3x+3) / 7x+6. Беда в том, что я привязан к средствам процессора 286 и команду fsin использовать не могу. Иду окольным путем, через процедуру вычисления частичного тангенса fptan. Пока возникли две проблемы:
1. Решительно не хочет правильно разделить pi на 4. Это переменная four в формате слова. Эксперименты с присвоением ей другого формата (dq) или обозначения (например, 4.0. вместо 4) дают еще более неправильный результат.
2. После завершения энтой процедуры вычисления синуса возврат идет не к месту ее вызова, а к началу кода.
Что за напасть?
.286p
.model small
.stack 100h
.data
mes db 'Operands not comparable', 13, 10, '$'
a dw 1
b dw 5
x dd 1
n dw 0
d dw 20
eps dd 0.0001
two dw 2
three dw 3
seven dw 7
six dw 6
h dq ?
y dq ?
z dq ?
NL db 0Dh, 0Ah, "$"
STATUS DW ?
FOUR dw 4
C3 EQU 40H
C2 EQU 04H
C1 EQU 02H
C0 EQU 01H
.code
CalcF macro; На вершине стека д.б. "x"
fimul three
fiadd three
call sin
fstp y
fld x
fimul seven
fiadd six
fld y
fdivr
endm
iCalcF macro param
fild param
fimul three
fiadd three
call sin
fstp y
fild param
fimul seven
fiadd six
fld y
fdivr
endm
Сalc_h macro
mov cx, n
add cx, d
mov n, cx
dec cx
; вычисляем шаг
finit
fild b
fisub a
fidiv n
fst h ; Сохраняем шаг
endm
main proc
mov ax, @data
mov ds, ax
outer_:
fld y
fstp z
Сalc_h
iCalcF b
fstp y
iCalcF a
fadd y ; Складываем
fidiv two ; Делим сумму на 2
fstp y ; Сохр. начальное приближение
; внутренний цикл - вычисляем ФУНКЦИЮ
fld x ; X в стек сопроцессора
inner_loop:
fadd h ; X <- X + h
CalcF
fadd y
fstp y ; Сохраняем новое значение
loop inner_loop
fld y
fmul h
fst y
call outfloat
call OutInt ;выводим актуальное n
finit
fld y
fsub z
fabs
fcomp eps
fstsw ax
sahf
jp m2
jz m1
jc exit
jmp outer_
m1: jmp outer_
m2:
MOV DX, offset mes
mov Ah,09
int 21h
exit:
mov ax, 4c00h ;
int 21h ;
main endp
outfloat proc near ;вывод числа
push ax
push cx
push dx
push bp
mov bp, sp
push 10
push 0
; Проверяем число на знак, и если оно отрицательное,
ftst
fstsw ax
sahf
jnc @of1
; то выводим минус
mov ah, 02h
mov dl, '-'
int 21h
; и оставляем модуль числа.
fchs
@of1: fld1
fld st(1)
fprem
fsub st(2), st
fxch st(2)
xor cx, cx
@of2: fidiv word ptr [bp - 2]
fxch st(1)
fld st(1)
fprem
fsub st(2), st
fimul word ptr [bp - 2]
fistp word ptr [bp - 4]
inc cx
push word ptr [bp - 4]
fxch st(1)
ftst
fstsw ax
sahf
jnz short @of2
; Теперь выведем её.
mov ah, 02h
@of3: pop dx
add dl, 30h
int 21h
; И так, пока не выведем все цифры.
loop @of3
; Теперь за дробную часть, для начала проверив её существование.
fstp st(0)
fxch st(1)
ftst
fstsw ax
sahf
jz short @of5
; Если она ненулевая, выведем точку
mov ah, 02h
mov dl, '.'
int 21h
; и не более четырех цифр дробной части.
mov cx, 4
; Помножим дробную часть на десять,
@of4: fimul word ptr [bp - 2]
fxch st(1)
fld st(1)
; отделим целую часть
fprem
; оставим от произведения лишь дробную
часть,
fsub st(2), st
fxch st(2)
; сохраним полученную цифру во временной ячейке
fistp word ptr [bp - 4]
; и сразу выведем.
mov ah, 02h
mov dl, [bp - 4]
add dl, 30h
int 21h
; Теперь, если остаток дробной части ненулевой
fxch st(1)
ftst
fstsw ax
sahf
; и мы вывели менее четырех цифр, продолжим.
loopnz @of4
; Осталось убрать мусор из стэка.
@of5: fstp st(0)
fstp st(0)
leave
mov AH,9
mov dx, offset NL
int 21h
pop dx
pop cx
pop ax
ret
outfloat endp
OutInt proc near
push cx
push dx
push bx
push ax
mov ax,n
xor cx, cx
mov bx, 10
l1:
xor dx,dx
div bx
push dx
inc cx
test ax, ax
jnz l1
mov ah, 02h
l2:
pop dx
add dl, 30h
int 21h
loop l2
mov AH,9
mov dx, offset NL
int 21h
pop ax
pop bx
pop dx
pop cx
ret
outint endp
SIN PROC near
PUSH DS
SUB AX, AX
PUSH AX
MOV AX, CS
MOV DS, AX
MOV ES, AX
DO_AGAIN:
FLDPI ; PI ; X
FIDIV FOUR ; PI/4 ; X
FXCH ; X ; PI/4
FPREM ; R ; PI/4
FSTSW STATUS
FWAIT
MOV AH, BYTE PTR STATUS+1
TEST AH, C1 ; Определяется, необходимо ли вычитание PI/4
JZ DO_R ; Если 0, то не нужно
FSUBRP ST(1), ST(0) ; A = PI/4-R ; ?
JMP SHORT DO_FPTAN
DO_R:
FXCH ; PI/4 ; R
FCOMP ; R ; ?
DO_FPTAN:
FPTAN ; OPP ; ADJ Где
OPP/ADJ=Tan(A)
;----- Определение того, что нужно - синус или косинус
TEST AH, C3 or C1
JPE DO_SINE
FXCH ; ADJ ; OPP
DO_SINE: ; D ; N
; Вычисление N/SQR(N**2 + D**2)
FMUL ST(0),ST(0) ; D**2 ; N
FXCH ST(1) ; N ; D**2
FLD ST(0) ; N ; N ; D**2
FMUL ST(0),ST(0) ; N**2 ; N ; D**2
FADD ST(0), ST(2) ; N**2 + D**2 ; N ; D**2
FSQRT ; SQR(N2 + D2) ; N ; D**2
FDIVRP ST(1) ; SIN(X) ; D**2
FXCH ST(1) ; D**2 ; SIN(X)
FCOMP ; SIN(X) ; ?
Test ah, C0
jz return_inst
fchs
return_inst:
RET
SIN ENDP
end main
Автор: Hey 8.10.2012 15:55
Порядок, нашел ошибки. Из процедуры SIN надо было убрать все эти DS-ES и сразу переходить к вычислениям. Но и в теле программы пришлось кое-что подправить...)